Anthropicが「3つのバグ」を認めた
2026年3月から4月にかけて、Claude Codeが劣化したという報告がSNSで相次いだ。「最近、急に頭が悪くなった」「コードが雑になった」「指示通りに動かない」── タイムラインに同じ嘆きが流れ続けた。
4月23日、Anthropic は公式ブログで3つのバグの重なりを認めた。
- 3月4日:UIフリーズ対策で reasoning effort を high から medium に変更。「間違ったトレードオフ」と後に認定され、4月7日に revert。
- 3月26日:idle セッションの思考履歴削除バグで、毎ターン削除が発動。Claudeが「物忘れと反復」を起こす。4月10日に修正。
- 4月16日:応答冗長性削減プロンプトでコーディング品質が悪化。4月20日に revert。
「APIは影響を受けていない」とAnthropicは明記している。劣化は事実だ。しかしその前提は揺るがない。
そして同じ春、私のClaude Codeは劣化しなかった。
同じ環境で、なぜ揺れる人と揺れない人がいたのか
私が使っていたのは、騒動と同じ Pro / Max プラン、同じ Claude Code、同じ Sonnet/Opus。環境は等しい。
差は、AIを「アシスタント」として使ったか、「判断のオーケストレーション環境」として設計したかだった。
「設計」と書くと大げさに聞こえる。実態はシンプルだ。判断主体・判断の素材・実行ノウハウを、それぞれ別のレイヤーに置いた。それだけだ。揺れる相手と踊らずに済んだのは、構えを別の場所に置いていたからに過ぎない。
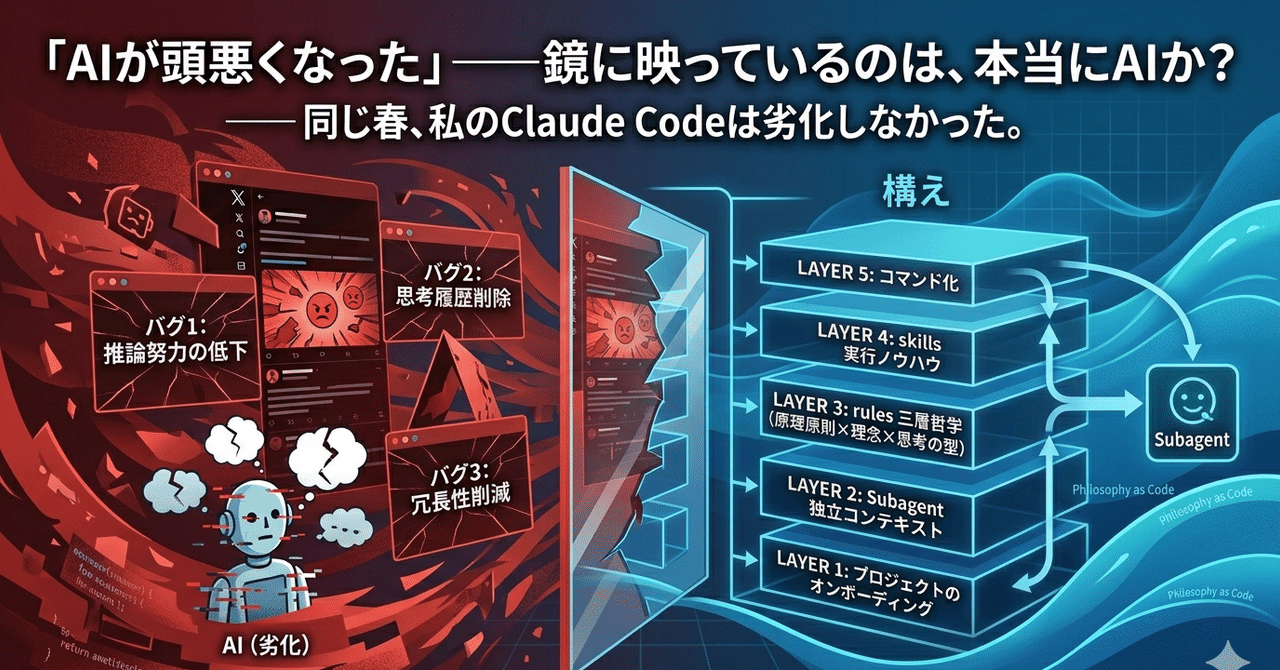
Claude Code 設計の全5層
私のClaude Codeは、以下の5層で動いている。
Layer 1 — CLAUDE.md:オンボーディング層
リポジトリの目的、ユーザー背景、ディレクトリ構造、基本コマンドだけが書かれている。セッション開始時に1度だけ読み込まれ、システムプロンプトに常駐する。だから軽く保つことが原則だ。判断ロジックはここに書かない(公式のBest Practicesでも200行以下が推奨されている)。
Layer 2 — Subagent:判断主体の独立化
Subagent は、Agent tool 経由で呼び出されるたびに新規インスタンスとして起動する。親会話の履歴は引き継がない。親から渡されるのは、Agent tool の prompt に明示的に書いた情報だけだ。
これは副作用ではなく、設計上の本命だ。判断が独立したコンテキストで動くということは、メインセッションの「揺れ」から切り離される、ということでもある。
Layer 3 — rules:判断の構造体「三層哲学」
判断の構造を、三つの層で定義している。
- LAYER 01 原理原則 ── 「LLMは確率分布から答えを拾うため揺らぐ」「コンテキスト膨張で精度低下」など、世界の構造的事実
- LAYER 02 理念(意念) ── 同じ原理原則の上で、組織が何を最優先するかの宣言。例:「正しさの定義を先に決め、それに向かって実装を収束させよ」
- LAYER 03 思考の型 ── 原理と理念をどう接続して判断に至るかの回路。武術の「構え」に相当する
「まず全体を見る」「逆から考える」「一度手放して再構成する」── 思考の手順が、ここで定義されている。
Layer 4 — skills:実行ノウハウ
判断の後で実装するための、具体的な知識。TypeScript の非同期処理、テスト命名規則、リファクタリング手順、ドメイン固有の作法など。「How」の引き出しがここに集約されている。
Layer 5 — コマンド化
/コマンド名 引数 で Subagent を呼び出す設計。ユーザー入力 → エントリーポイント → Subagent 新規起動 → rules と skills を参照 → 判断実行、という一連のフローが、コマンド単位で再現可能になっている。
3つのバグからの保護メカニズム
バグ1(reasoning effort 低下)への耐性
思考を浅く済ませてしまうバグに対し、Subagent はコマンド経由で起動するたびに rules の三層哲学を経由した判断構造 を読み込む。簡単な質問でも原理原則 → 理念 → 思考の型を経由するため、思考量を勝手に下げにくい設計になっている。
バグ2(思考履歴削除)への耐性
メインセッションの reasoning history が削除されても、判断は「コマンド経由で Subagent 呼び出し」で実行される。Subagent は新規インスタンスとしてメインセッション履歴を引き継がない独立コンテキストで動くため、バグの影響圏外で動作する。
これは偶然の防御ではない。判断構造をメインセッションから切り離した設計の、副作用としての耐性だ。
バグ3(verbosity 削減)への耐性
応答短縮プロンプトの影響下でも、Subagent 定義ファイル側の構造化された判断フローが、思考の手順を保つように働く。完全防御ではないが、判断の骨格は崩れにくい。
構えという思想 ── 武術からのアナロジー
私はジークンドー(截拳道)を実践してきた。武術には「構え」という概念がある。型ではない。型に縛られないための、判断の根幹だ(この思想の出発点は「考えるな、従え」の時代は終わったに書いた)。
ブルース・リーは言った。
Be water, my friend.── ブルース・リー
水はどんな器にも適応する。揺れる相手にも対応できるのは、構えが定まっているからこそだ。
宮本武蔵は『五輪書』で「一つの道を知れば、万事に通ず」と書いた。太刀の扱いを極めた者は、槍も扇子も原理で扱える。AI も同じだ。プロンプトの形ではなく、原理を掴んだ者だけが、ツールの揺らぎを超えていける。
ツールが揺れても、構えが揺れなければ崩れない。
鏡 ── AIではなく、構えを疑う
「AIが頭悪くなった」と感じたとき、立ち止まって考えてほしい。
鏡に映っているのは、本当にAIだろうか。
人間はこれまで、ルールの隙間を暗黙のうちに埋めてきた。「ここはこういう意味で言ったよね」「これくらいの粒度でやって」── 文脈と判断軸を、無自覚に補完していた。AIはそれを補完しない。判断の上位原則がなければ、出力は揺れ続ける。揺れ続ける出力を見て「AIが劣化した」と感じる、その感覚そのものが、構えの不在を映している。
武術の言葉でこう言う。
相手を疑う前に、己の構えを疑え。
これは「正解」ではない、一つの考え方だ
ここまで書いた設計は、ひとつの考え方にすぎない。
「メソッドを真似すれば同じ結果が出る」とは思っていない。私の設計は、武術稽古の何百回・何千回の研鑽の上に成り立っている。同じディレクトリ構造を作っても、同じ哲学を持てるとは限らない。
組織には、組織の言葉がある。原理原則も、理念も、思考の型も、自分たちの中にしか存在しない。引き出すのは対話だ。
Philosophy as Code が引き出すもの
弊社 B-LAND は「Philosophy as Code」というサービスを提供している。
メソッドとノウハウは公開する。ホワイトペーパーも、Skillの仕組みも、Subagentの設計図も、すべてオープンだ。
しかしWhyを定義する力は、真似できない。組織のなかにすでにある暗黙知を、対話で引き出して三層哲学に編む。1on1コーチングがその場になる。引き出すのは私たちだが、定義するのは組織自身だ。
おわりに:構えを持つ者が、揺らぎを超える
ツールは揺れる。モデルは変わる。バグは混じる。それは前提だ。
その前提のもとで、組織が揺らがずに前に進む方法は、ひとつしかない。構えを持つこと。判断の上位原則を、自分たちの言葉で定義すること。
「AIが頭悪くなった」と感じたあなたへ。
鏡を見直す時間が、いま、来ている。